
Conformal Redacted Word and Part-of-Speech Predictions
Mentors: Jonathan Williams & Neil Dey
Team: Jack Ferrell, Carolina Kapper, Maxwell Lovig, & Emi Planchon
Project Overview Video and Corresponding Slides
Project Overview:
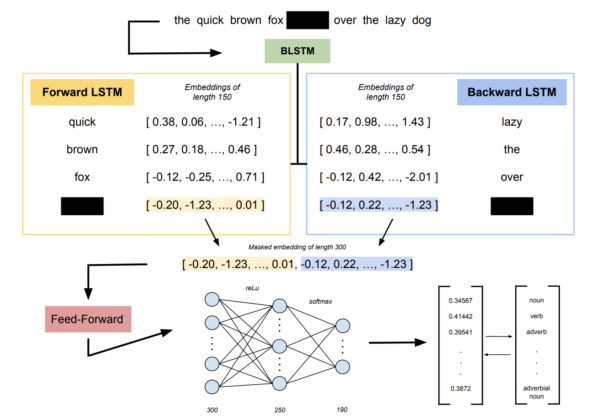 Modern machine learning algorithms are capable of providing remarkably accurate predictions, however, questions remain about their statistical interpretability. These techniques are referred to as “black box”, where a single point estimate is generated, but it is unclear exactly how or with what degree of certainty the prediction is made. Unlike conventional machine learning models, conformal predictors (CP) output predictive regions that correspond to a given confidence level. This is analogous to a confidence interval for more traditional statistical models. CP comes with the added power of guaranteeing the probability of an individual prediction being wrong, allowing us the flexibility of choosing an acceptable error rate. The original CP method is prohibitively computationally expensive, so we explore the significantly cheaper but slightly less accurate inductive conformal predictions (ICP) on the tasks of text in-filling and part-of-speech tagging. We use the Brown Corpus from Brown University as our input, and we use several machine learning algorithms to predict masked words and their parts of speech. Through ICP, we analyze the part-of-speech-tagging abilities of a BiLSTM neural network and BERT transformer-based models, and extend our use of BERT to text in-filling.
Modern machine learning algorithms are capable of providing remarkably accurate predictions, however, questions remain about their statistical interpretability. These techniques are referred to as “black box”, where a single point estimate is generated, but it is unclear exactly how or with what degree of certainty the prediction is made. Unlike conventional machine learning models, conformal predictors (CP) output predictive regions that correspond to a given confidence level. This is analogous to a confidence interval for more traditional statistical models. CP comes with the added power of guaranteeing the probability of an individual prediction being wrong, allowing us the flexibility of choosing an acceptable error rate. The original CP method is prohibitively computationally expensive, so we explore the significantly cheaper but slightly less accurate inductive conformal predictions (ICP) on the tasks of text in-filling and part-of-speech tagging. We use the Brown Corpus from Brown University as our input, and we use several machine learning algorithms to predict masked words and their parts of speech. Through ICP, we analyze the part-of-speech-tagging abilities of a BiLSTM neural network and BERT transformer-based models, and extend our use of BERT to text in-filling.